
Bring Back the Weekly Newspaper
No, really

On election night (eons ago!) last November, I was struck by how much people hated the return of the dreaded New York Times needle.
Well, the hatred was understandable in many ways. It recalled the utter shock many people had experienced in 2016, when the needle started predicting that Donald Trump would win.
I think this feeling of anxiety was also worsened by the needle’s annoying user interface—it was jittery for no reason that I can tell, except to increase the feeling of tension, for example. It was designed to keep you anxious. Being made to feel extra tense on top of an already actually high-stakes, tense moment clearly does not sit well with most people.
So when 2020 came around, and the needle appeared again, there was a lot of groaning and complaining.
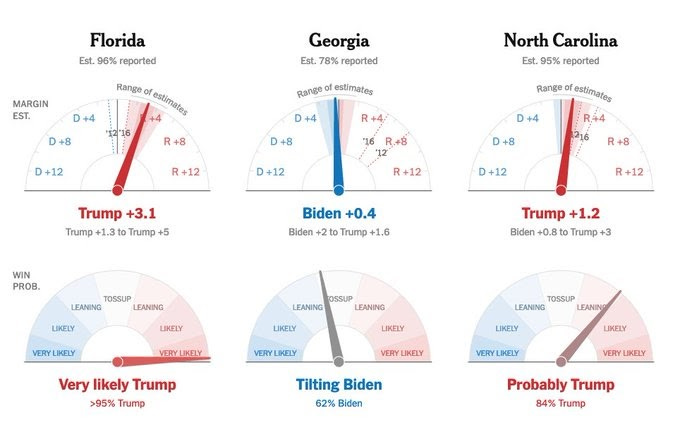
I had the opposite reaction. The needle was good, and really useful, compared to everything else we had before: the forecasts that were just polls being modeled, and the raw returns, which did not take into account where the returns were coming from.
In fact, I was really not fond of the election forecasts leading up to the election. They are model-heavy and data-light in comparison with real-time calculators like the needle. They model voter behavior before anyone has voted, something that’s really hard to predict, especially during a pandemic. So it’s not that modeling was bad per se. But its quality depended on whether a given model was based on data like actual votes(!) but using models to account for complexities like the difference in voting counting times, and the demographics of different regions—things the needle can incorporate— versus shaky data (polls) made-up for with modeling.
Incidentally, I wrote a piece on that before the election:
One key problem in 2016 was the assumptions pollsters made when modeling the electorate — the people who would actually show up to vote. Pollsters were a little off in estimating the educational level of the electorate, especially in the Midwest. What’s more, people who settled on a preference late were a bit more prone to vote for Mr. Trump, and his supporters were a bit more likely to turn out than the models assumed. Even small shifts like that matter greatly; if it’s happening in one state, it’s probably happening in many similar states.
In 2020, it was even harder to rely on polls or previous elections: On top of all the existing problems with surveys in an age of cellphones, push polls and mistrust, we’re in the middle of a pandemic. What would the unprecedented early voting numbers mean when polls don’t necessarily stop polling those who already voted? How would the early forecasts that run for many months before the election, and so are even more uncertain, affect those who vote early? Would the elderly, at great risk from the pandemic, avoid voting? How would voter suppression play out? Would Republicans end up flocking to the polls on Election Day? These were big unknowns that added great uncertainty to models, especially given the winner-takes-all setup in the Electoral College, where winning a state by as little as one-fourth of 1 percent can deliver all its electoral votes.
This is different from what the needle does. On election nights, returns do not arrive in a random manner. Smaller places (rural, thus Republican) can count faster, while some larger urban centers (which lean Democratic) count slower. The needle takes actual data (votes!) and adjusts for the way they come in, and also uses comparisons with the past to predict where things have actually already moved by looking at votes actually cast (the returns!).
In contrast, raw returns can be highly misleading when they don’t take this reality into account.
And that’s exactly what we know Trump and his team were hoping for. They hoped that the early, skewed results would make it look like he was winning, so he could draw it out, or claim that it was stolen later. Trump won Florida, which reported early, but lost Georgia and Pennsylvania, where the results were reported later, and there are indications that this wasn’t even a coincidence:
Early returns on election night showed Trump ahead in the state that had helped him win the White House in 2016. But a Pennsylvania law that Republicans resisted changing barred counties from opening more than 2.5 million mail-in ballots until Election Day. As a result, it took days to tally all the votes, particularly in Democratic strongholds of Philadelphia and Pittsburgh, where many Biden supporters had voted by mail to avoid visiting polls during the coronavirus pandemic.
As the votes were counted, Biden closed Trump’s lead and then pulled ahead — a phenomenon that political experts had predicted would occur. Four days after the election, major news organizations declared Biden the winner of Pennsylvania’s 20 electoral votes. On Nov. 24, Pennsylvania Secretary of State Kathy Boockvar (D) formally certified Biden’s victory by a margin of over 80,000 votes.
But the slow count offered Trump an opening. On Nov. 7, his personal attorney Rudolph W. Giuliani and other allies held a freewheeling news conference in the parking lot of a Philadelphia landscaping business. Giuliani declared the election was being stolen from Trump in the city, which he said had “a sad history of voter fraud.”
In other words, Trumpworld was counting on the initial impressions of the election results being sticky. And first impressions are indeed very sticky.
I’ve been noting this stickiness throughout the pandemic as well. I’ve been struck by how hard it is to shift from initial anecdotal evidence to different theories, even when we have contrasting, systematic data—a lot of data—afterwards.
For example, more than sixteen months in, there is still a widespread assumption that Huanan Seafood market was the source of the outbreak. Many people seem to think we know for sure that that’s where it started. In reality, the market was where the virus was first detected. It might have been where it started, but that’s far from clear, and in fact, from the very first days of the pandemic, there was a strong reason to treat seafood market-source as a hypothesis, not something proven.
Here’s the first epidemiological report out of China, published in The Lancet, co-authored by many Chinese scientists, naturally, on January 24th 2020.
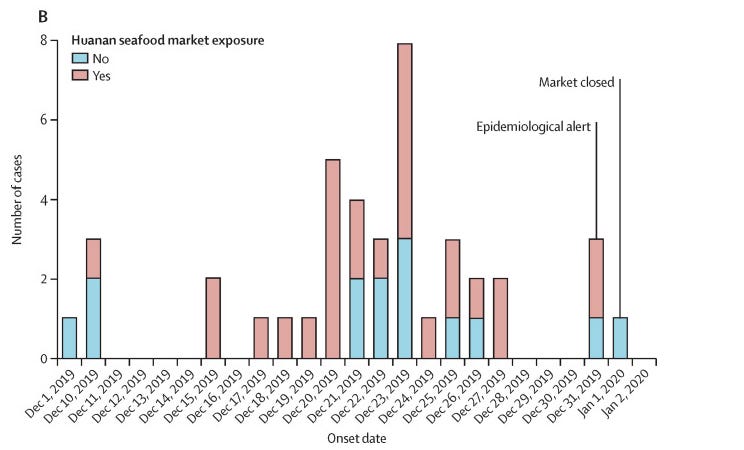
As you can see from the chart, 14 of the 41 cases had no exposure to the seafood market, including, crucially, the earliest known three cases. This would be compatible with the scenario where the virus was already circulating in Wuhan but had its first outbreak in the seafood market.
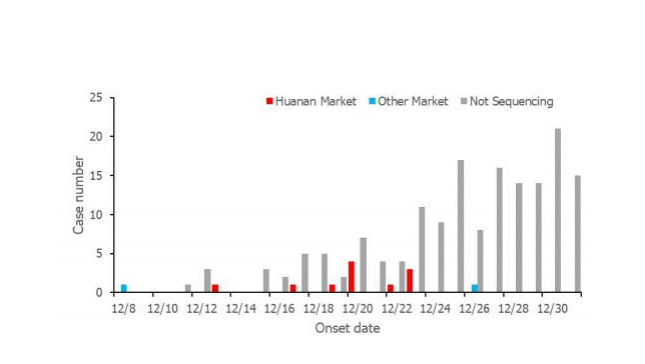
About a year later, we got another update from the WHO origins investigation — a flawed and limited source, in my view, but we can at least look at this part. It tells a similar story:
If you are wondering about the discrepancy between the two reports, let me take a minute to outline the official explanation. (Feel free to skip if not of interest!)
The WHO team was told that the first three cases had been excluded based on “clinical features.” I can’t fully make sense of the three exclusions. The Lancet article does say that, “Of 59 suspected cases, 41 patients were confirmed to be infected with 2019-nCoV. The presence of 2019-nCoV in respiratory specimens was detected by next-generation sequencing or real-time RT-PCR methods.” But the WHO report then excludes three people who were presumably PCR confirmed by the earlier Lancet article? The first one was reported as excluded because “he responded to antibiotics” (which I know from reports can happen if the COVID-19 patient has a secondary infection as well, and also that case later did test positive via PCR according to the WRO report). The second one was excluded because this person was reported as having “remained negative on SARS-CoV2 laboratory testing throughout a longer admission period ending in mid-February 2020” (but had tested PCR positive earlier as per Lancet?). The third just says that “blood collected in April 2020 was reported negative for SARS-CoV-2-specific antibodies” (no PCR test as per Lancet?)
Back to the topic.
Still, even with the exclusions, this is what the WHO study concludes:
Many of the early cases were associated with the Huanan market, but a similar number of cases were associated with other markets and some were not associated with any markets. Transmission within the wider community in December could account for cases not associated with the Huanan market which, together with the presence of early cases not associated with that market, could suggest that the Huanan market was not the original source of the outbreak. Milder cases that were not identified, however, could provide the link between the Huanan Market and early cases without an apparent link to the market. No firm conclusion therefore about the role of the Huanan Market can be drawn.
(You might be wondering what the “other markets” were. Good question: the only one mentioned by name that I could find is a supermarket, but the report was so short on crucial details on so many questions, and that’s just one more of them. From the cases where information was available, WHO report says 28% had exposure to the Huanan market only, but does not name the other markets or their characteristics).
Thus, even if one takes the exclusions with a grain of salt (and puts aside our hopes for clarification), the Huanan market has still never been nailed definitely as the source of the outbreak, but almost certainly the first major superspreader event. Still, the market rarely gets reported as being “the first site of detection, and almost certainly the first superspreader event, and it may or may not be the source of the outbreak.”
Why? Well, obviously, the latter is a mouthful. But also, I think it’s just straightforward: first impressions are extremely sticky.
(And it’s important to note that the initial Lancet article was written by Chinese scientists themselves, during that early period where they seemed to be publishing openly and very rapidly. I’ve always been impressed by their speed and the volume of information we got, and I remain angry that we did not take their work seriously. One cannot chalk up the Western media’s reporting of the seafood market as the source to being a cover-up, whatever else may have happened later. The manta of the seafood market-as-source results in more sticky first-impressions, insufficient efforts to report updated data, and the tendency to just repeat earlier claims).
This has been a pattern. There was an initial preprint of an increased likelihood of Pfizer “vaccine breakthrough” for the B.1.351 variant Israel based on eight (!) breakthrough cases (!) that was quite speculative and not that worrying. (I wrote about this earlier: it’s fine to keep an eye on such things, but the little study did not require the panic it endangered).
Panic like these headlines, which ricocheted around the world:

Meanwhile, later, we had a full study from Qatar showing… drumroll… that the Pfizer vaccine was indeed quite effective against B.1.351. It recruited 385,853 people with one and 265,410 with two doses, so it was quite large. The study showed vaccine effectiveness against severe, critical, or fatal disease due to infection with any SARS-CoV-2 was almost 100%, and for B.1.351, it was 100.0 [CI:73.7–100.0].

The amount of attention that later actual systematic study with a large N got is left, as an exercise to the reader.
Well, actually one part of that study did get attention: notice the low effectiveness numbers after the single dose? The researcher later confirmed that they had included the first 14 days as well, during which the vaccine is not expected to be that useful, since the immune response takes time. The researcher hadn’t really thought about that issue, I guess, since this wasn’t a single-dose effectiveness study. Anyway, yes, there was a freakout over that, too, even though it contradicted every previous study we had, so people should have at least paused a second and read the appendices before freaking out, but that wasn’t to be either.
I’m not laying all this out as a blame game. I’m just saying that the way our brains absorb information is not conducive to being truly informed in a useful manner. We pay undue attention to negative, alarming information and initial impressions, which register strongly, and just can’t balance that with correcting and updating the impressions with later data.
I realize this is the “solution” graph, but I don’t have one. This isn’t just a media, or a social media, or human nature problem: it’s all of the above. Plus, paying attention to negative, alarming information is natural and can even be useful if one was in an immediate threat environment—like, say, the savanna during the Pleistocene era when our attention systems were evolving. It just doesn’t work to our advantage, though, in a mediated environment where the incentives are structured differently. I’d almost want a newspaper that reported last week’s news, and only that. Whatever didn’t survive as news probably isn’t worth reading about anyway.
And on that note, let’s all go refresh Twitter!
so well said! and so aware of our current reality when it comes to news coverage and consumption. thank you for the reminder of how important it is to calm down and slow down as we try to navigate all the many, many “facts”
being presented to us these days. thank you!
I’ve spent the last week only consuming long-form news content, and (shocker) I now have a lot more bandwidth to take care of myself and those around me. Long-form news should really be the only news we touch, thanks for the post Zeynep!
Side note: I think I’m actually more well informed on the things that matter, too